{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://wenda.whatsns.com//data/attach/topic/topich3rOc0.jpg', '推荐 刘光景 的文章《GC实战—浮动内存导致的CPU过高调优》','https://wenda.whatsns.com/article-15524.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
系统的性能优化不单单是对JVM的参数调优,也不是某一段代码的改造,而是一个系统的工程,往往会出现牵一发而动全身,简单的解决,很容易治标不治本从而掩盖问题的本质,而这些深藏的问题才是我们解决问题关键。
本次的浮动内存发现就是一次扑朔迷离的查找过程,cpu利用率过高,常见的问题都是线程使用不当造成的。但从这个方向去解决,你会发现很难解决本次的cpu过高问题,甚至效果不明显,若是从整个系统的各个指标协同分析验证,才会找到解决的最佳方案。
一、现象
1.高峰期报警
服务一般的高峰期都是晚上的19点—22点左右,期间的访问QPS可达到日间的2倍左右,访问量过大,机房的机器报警就接踵而至:
load1过高4 以上,CPU利用率达到40%以上。
2.监控信息
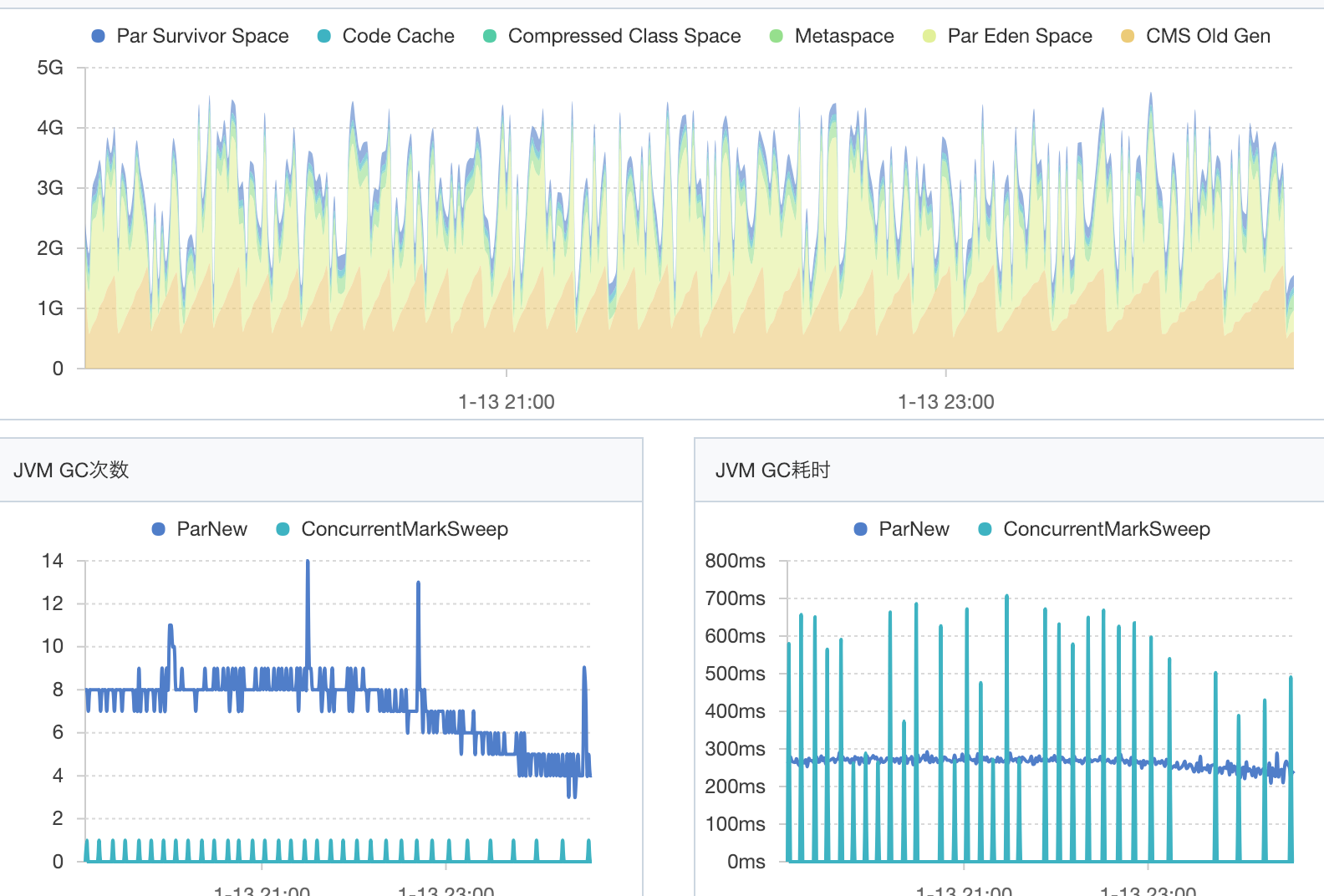
jvm内存
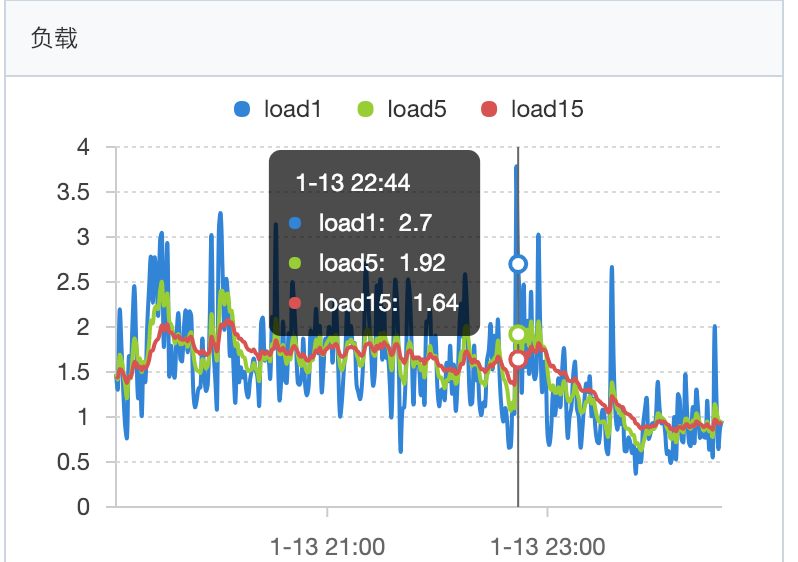
load
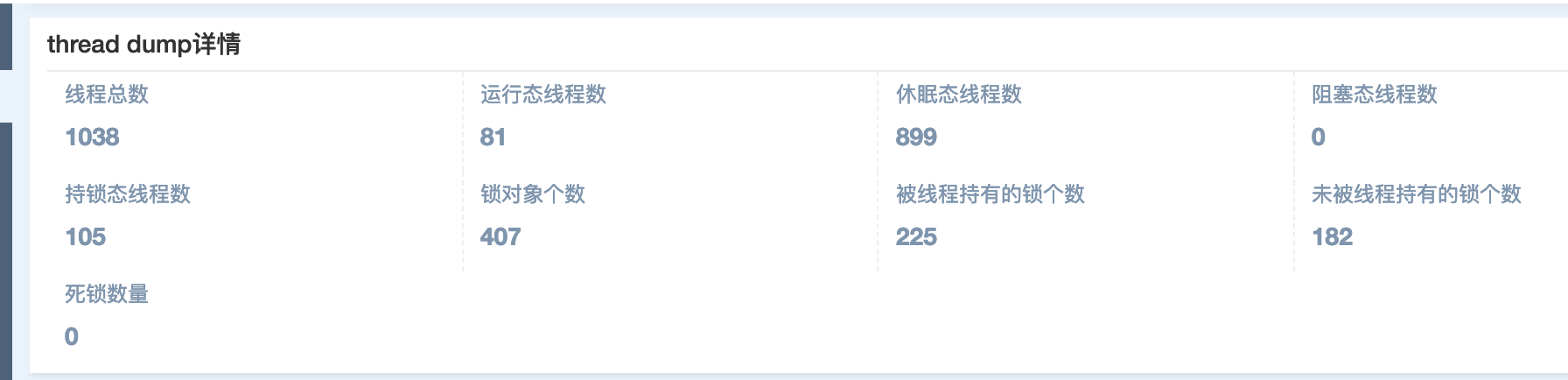
线程:
基于监控信息,我们发现以下问题:
10分钟 oldGC一次,每个波峰间隔时间8-10分钟左右.
CPU load过高,高峰期常在load1 在2-6之间浮动(4核),cpu利用率在14%—46%之间浮动。
jvm的 内存的波峰波谷过于频繁,不是长方体或椭圆形,呈锯齿状
线程过多,单个系统线程达到1000以上
二、分析
基于监控反馈的信息我们可以从以下几个点着手:
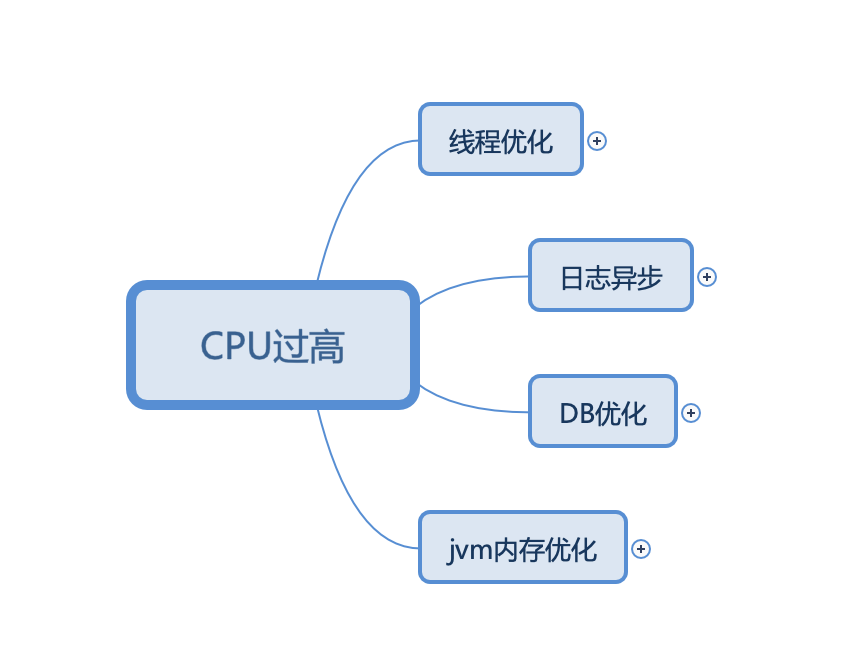
按道理来说CPU过高我们最应该从线程优化这个点入手,但通过监控信息的对比,我们发现,最严重的问题还是来之JVM内存管理.

从上图我们可以看出oldGC过于频繁:
10分钟 oldGC一次,每个波峰间隔时间8-10分钟左右.
这是一个重要的信息,我们可以理解为由于频繁GC导致CPU利用率上升。因此降低GC的频率是我们的首要任务。
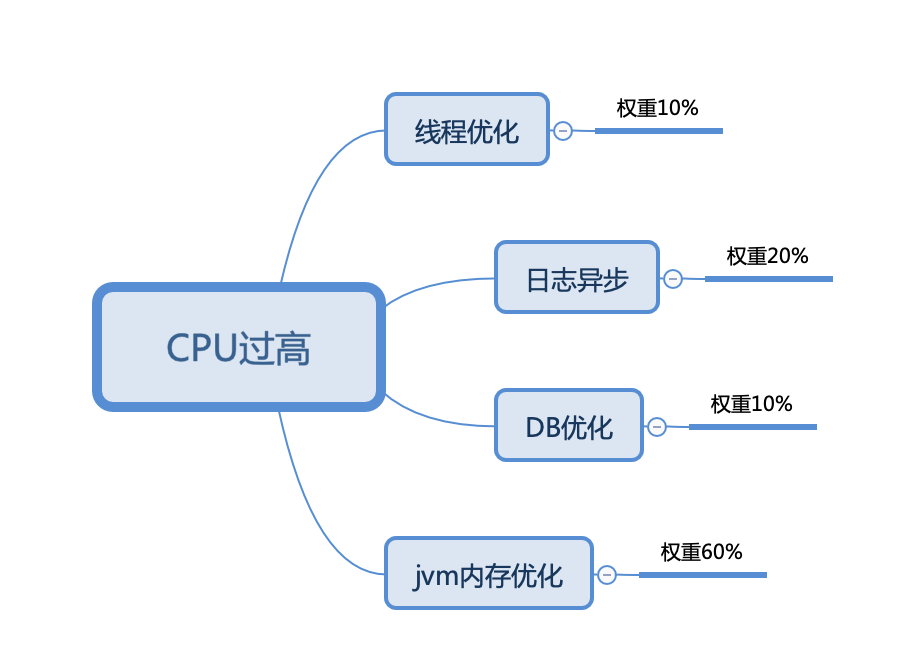
三、第一次尝试-GC调优
GC调优我们很容易想到的方案,是调整新生代和老生代的比率,提升新生代看空间,降低SurvivorRatio,从而延缓新生代的晋升。由于第一版的了解过于肤浅和紧急,我们的方案简单粗暴:
Total Head 提升1g
ParNew head 提升1g
SurvivorRatio 10->7
上面的结果可想而知,效果很勉强。
oldGC从8-10分钟,改变问10—12分钟,提升10%左右
CPU 利用率 高峰期最高46%,load1 (2-6)没变化
四、第二次尝试-浮动内存调优
鉴于第一次分析不仔细,我们在需要对jvm内存进行dump分析,看下具体是什么原因导致old不断GC。
我们借助以下工具:
Eagleeye
Zprofiler
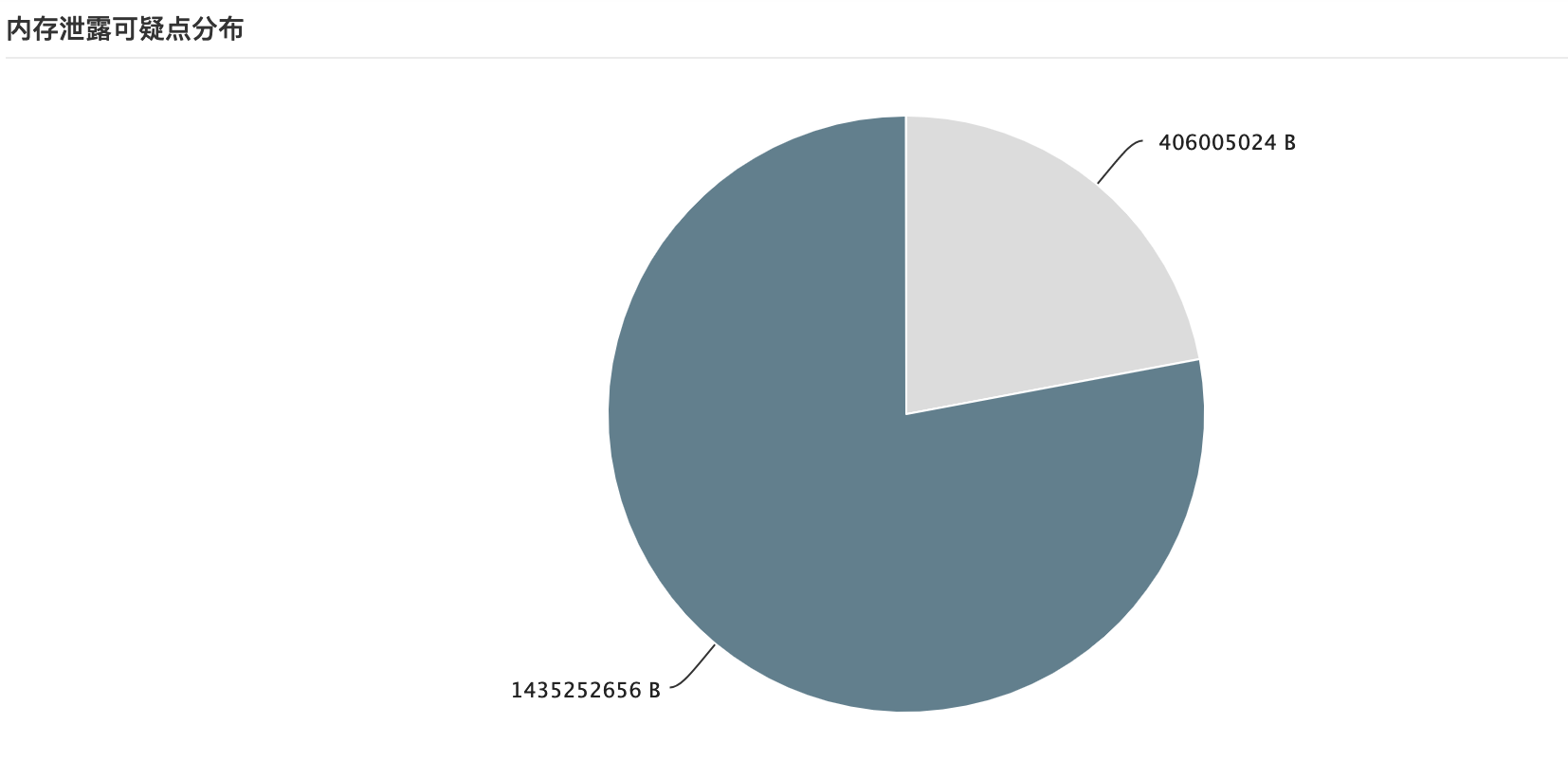
从dump下的head信息,我们看到,有两部分占用内存过高。
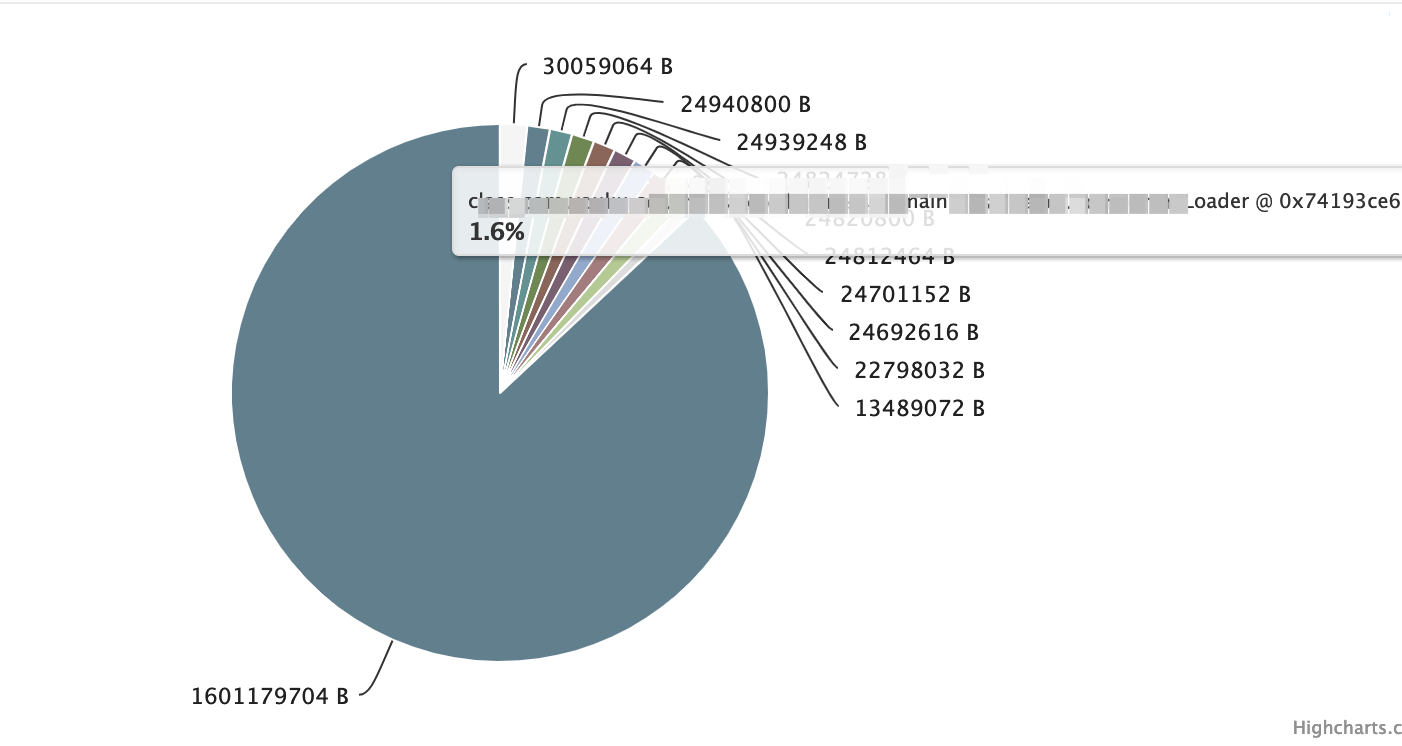
内存泄漏可疑点分析:
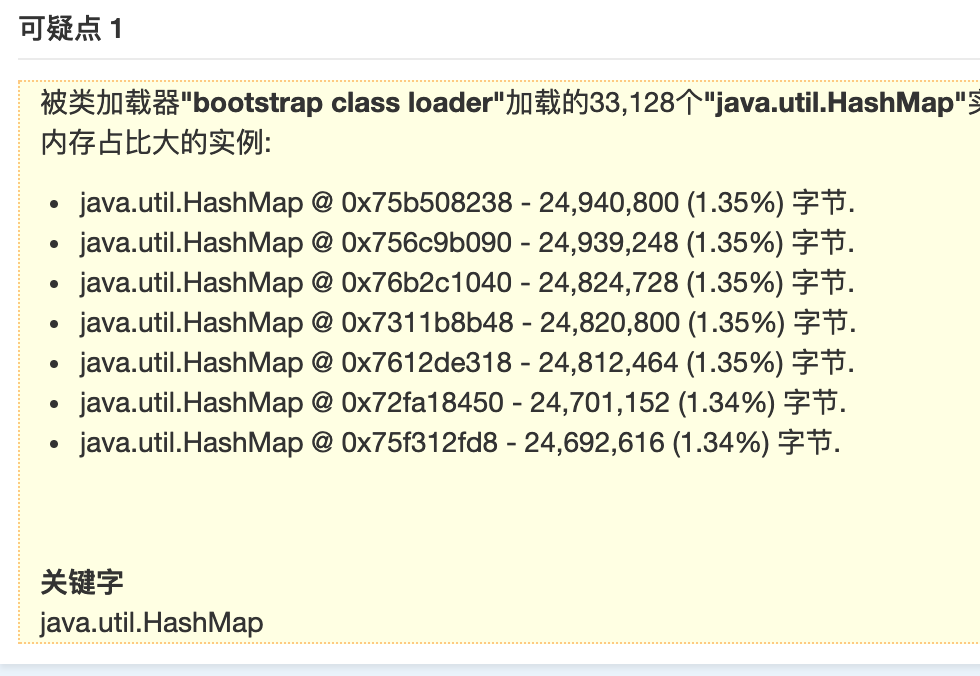
通过head占比分析,我们发现一些数据库load对象很可疑,使用了大量的hashMap缓存数据。通过追踪代码,我们发现以下问题:

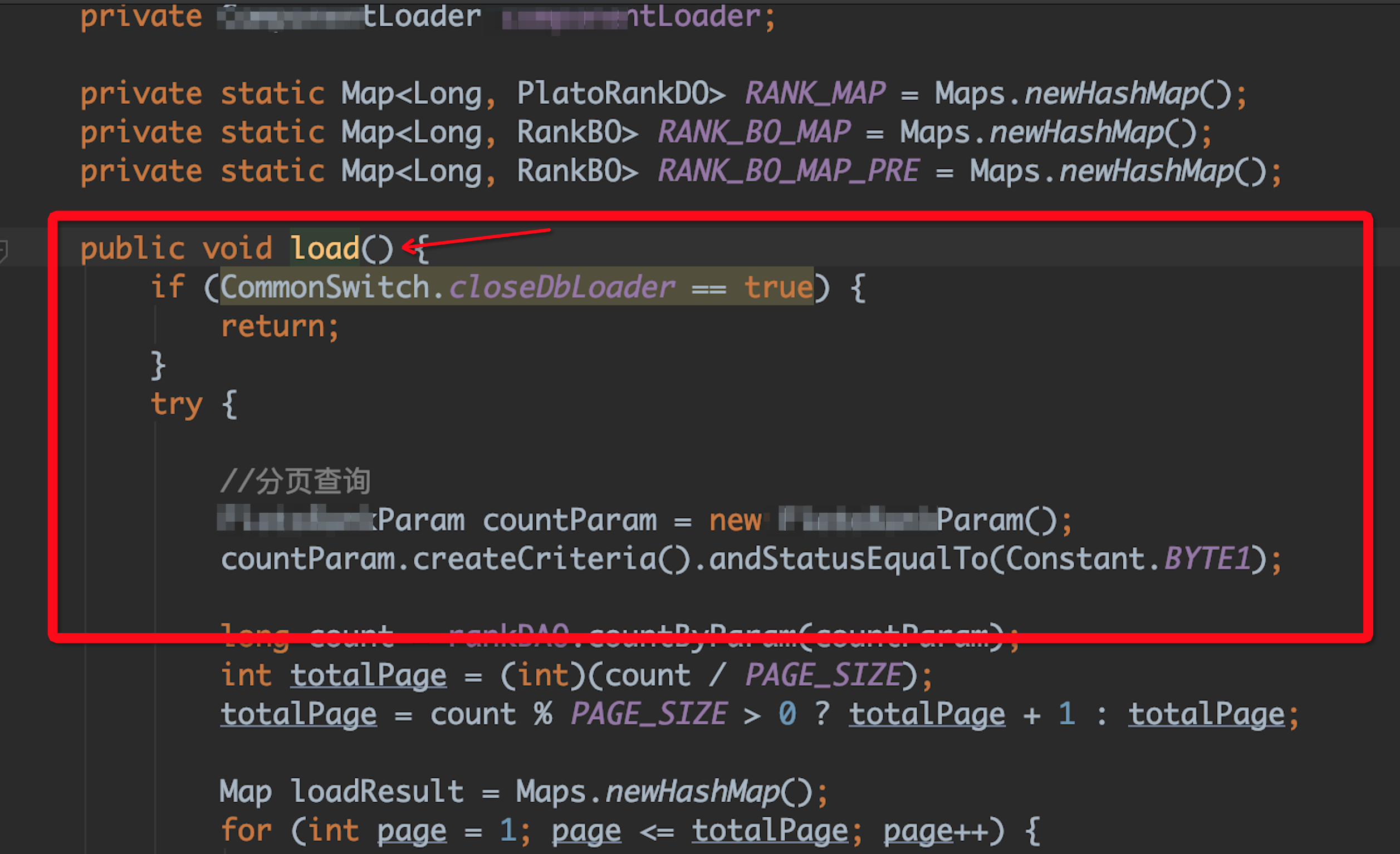
以上代码是从数据库定时load数据到内存中,每次load之后,之前的map对象被遗弃。造成的现象:
1.每隔一段时间(5分钟以内)会有一批大对象被释放
2.大对象会随着系统的运营时长以及新应用的加入,越来越大
3.浮动对象是用来解决缓存被动更新的问题
4.浮动大对象对GC造成很大的压力,大量的浮动对象在新生代没有被释放就晋升到老年代,造成老年代频繁GC
通过以上分析,我们可以定位频繁GC的主要问题就是 load里面的map,由于不断的定时废弃,造成了大量的浮动大对象GC。
通过扫描,我们发现系统中由于没有引入统一的缓存架构,大量需要缓存的代码,都采用这种 定时废弃的方式来进行。
如此多的代码,改动工作量还是很大的,这也促进我们对YKCache 框架的推出,YKCache主要用来改善缓存的统一管理接入工作,热点缓存的维护,以及多级缓存(local+tair+db)的支持。
YKCache特点:
1.多级缓存(local+tair+db),
2.热点数据支持自动维护。
3.地侵入接入,不改造代码
4.缓存支持主动更新和被动更新
在引入YKCache之后,我们对内存占比最大的两个load进行改造,同时移除某个二方包里面的loadMap,对此我们队head进行观察。
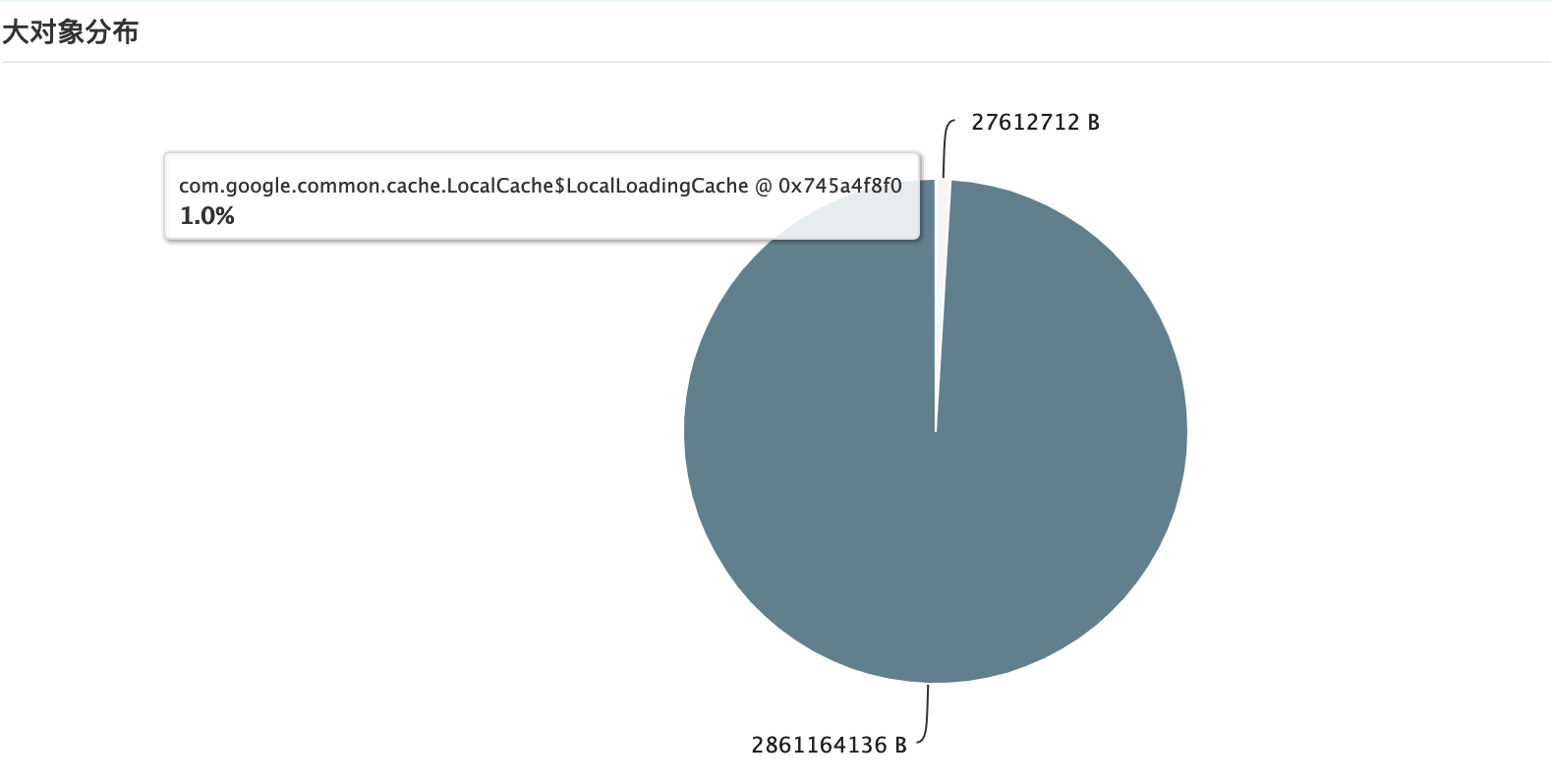
我们可以看到,load的map内存占用比降低了,因为缓存框架的引入,内存中不必缓存全部数据,只维护热点数据,内存占比降低了60%以上。同时热点缓存直接接入老年代,减少了老年代的GC频率。
但是这并不是终点,GC依然没有达到我们想要的目标。
五、第三次尝试-浮动内存+GC调优
以上我虽然解决的浮动内存的问题,但是我们还有一个问题忽略了,就是:
对象晋升的问题
1.对象晋升
我们知道对象晋升达到以下两个条件之一就可以发生:
1.minor gc 之后,存活于survivor 区域的对象的age会+1,当超过(默认)15的时候,转移到老年代。
2.动态对象,如果survivor空间中相同年龄所有的对象大小的综合和大于survivor空间的一半,年级大于或等于该年级的对象就可以直接进入老年代。
我们通过加入PrintTenuringDistribution 参数,观察对象的晋升情况。